Abstract
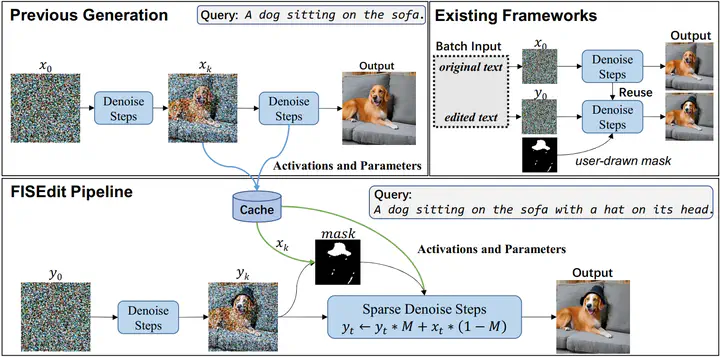
Due to the recent success of diffusion models, text-to-image generation is becoming increasingly popular and achieves a wide range of applications. Among them, text-to-image editing, or continuous text-to-image generation, attracts lots of attention and can potentially improve the quality of generated images. It’s common to see that users may want to slightly edit the generated image by making minor modifications to their input textual descriptions for several rounds of diffusion inference. However, such an image editing process suffers from the low inference efficiency of many existing diffusion models even using GPU accelerators. To solve this problem, we introduce Fast Image Semantically Edit (FISEdit), a cached-enabled sparse diffusion model inference engine for efficient text-to-image editing. The key intuition behind our approach is to utilize the semantic mapping between the minor modifications on the input text and the affected regions on the output image. For each text editing step, FISEdit can 1) automatically identify the affected image regions and 2) utilize the cached unchanged regions’ feature map to accelerate the inference process. For the former, we measure the differences between cached and ad hoc feature maps given the modified textual description, extract the region with significant differences, and capture the affected region by masks. For the latter, we develop an efficient sparse diffusion inference engine that only computes the feature maps for the affected region while reusing the cached statistics for the rest of the image. To further boost the efficiency, FISEdit fuses a series of time-consuming GPU kernels (e.g., sparse convolution, attention) to minimize memory accessing overheads. Finally, extensive empirical results show that FISEdit can be 3.4 times and 4.4 times faster than existing methods on NVIDIA TITAN RTX and A100 GPUs respectively, and even generates more satisfactory images.